
“Your fairness is not my fairness”: culture-driven perception shifts and what can be done about them
What is meant by “fairness” in tests? How is “fairness” related to “validity”? How do you preserve fairness of a test across languages and cultures in multilingual assessments? How do different cultural backgrounds influence fairness and test results? These are some of the issues addressed by cApStAn co-founder Steve Dept at a recent talk as part of the Fairness Speaker Series organised by MHS Assessment. Steve kicked off with a real-life example of a test where respondents from Southern European countries clearly put the focus elsewhere than Northern European respondents in answering the same question. This illustrated what Steve calls “culture-driven perception shifts”. Without a pilot test they would never have been picked up.
Consequences of culture-driven shifts
“Fairness” in assessments needs to be regarded first and foremost as a “validity” issue, said Steve. It is not so much about being equitable, which is of course very important, or about giving equal access to tests, or even about the level of difficulty of a test. “Your measurement must be valid and reliable, and in order to be valid and reliable it needs to be ‘fair’ in all different language versions”. Culture-dependent perception shifts in assessments can lead to construct-irrelevant variance. They can “blur” the construct, i.e., due to an external, unforeseen element, the assessment will not measure precisely what it intended to measure.
Why “fairness” needs to be addressed upfront
Fairness applies to test development as well as to test delivery and test maintenance. cApStAn’s job as a linguistic quality assurance provider is linked to test development. Twenty-two years ago, the company verified/validated translations produced by translation agencies, or by countries. Experience taught us that many (language-driven) meaning shifts and (culture-driven) perception shifts could be avoided by preparing a more suitable master version and, in recent times, cApStAn has shifted the focus of its work to “upstream”, pre-translation work.
Getting the source version right
The master version of an assessment needs to be as unambiguous as possible and as unidiomatic as possible. Once it has been scrutinised by experts in various fields and piloted in two, three, or four languages, it can be finetuned and only then be translated into multiple languages, and adapted to idiomatic English for use e.g., in Canada, or to a different flavour of English for, say, Nigeria or Singapore. The source version, or starting point, may be less interesting and more translatable. As leading experts in the field say, “the success and failure of the ask-the-same-question (ASQ) approach is largely determined by the suitability of the source questions for all the cultures for which it will be produced”. Indeed.

The fundamentals of test design
What is the purpose of the assessment? What construct do you wish to measure? Is that purpose the same for the source and target population? Do the constructs exist for the target populations and does their meaning remain the same? Does anything in the content put testees at an advantage or disadvantage in one or several of the target languages? These are the key issues cApStAn focuses on in its work. And when we talk about “adaptation” in the translation world of tests and assessments we mean “an intentional deviation from the source that is necessary in order to avoid putting testees at an advantage or disadvantage”
The importance of diversity of SMEs
Another question that is equally important in test design is whether the subject matter experts represent both the source and target population. This can really influence how you identify, detect and mitigate culture-driven perception shifts. Coming back to the example given at the beginning of Steve’s talk, no matter how much linguistic quality assurance is done you could still have “accidents”, items that do not work as expected; you would still have differential item functioning, and item bias. Pilots are crucial and should be conducted in at least in a subset of the target languages. And when the pilots are done there needs to be a volume of examinees sufficiently large to support an empirical analysis of fairness.
How do you validate a test?
In some of the terms of reference we read that “each item in the test should examine the same skills and invoke the same cognitive process as the original version, while being culturally appropriate within the target country”. In reality, no linguistic quality assurance process can guarantee this. We can go a long way in avoiding some of the typical item biases or differential item functioning but direct validation remains tricky. Indirect validation is the way, through the analysis of results, by looking at the item discrimination, the fit, the DIF analysis for groups of respondents. A good way to optimise this process is to set up multidisciplinary task forces at item development stage.
Why item writers and linguists should collaborate
Item developers and linguists come from two different worlds and have different perspectives. Item developers carefully craft their questions and focus on subtle wording, which is supposed to elicit certain cognitive strategies in respondents, or not. Linguists focus on syntax and grammar, register and phraseology, and will avoid repetition, awkwardness or unnecessary complexity. For example, if a test author has used the same word three times the linguist may (to show off his/her skills) translate with three different words, but this introduces a level of difficulty that was not present in the original. It is essential to bring these two worlds together.
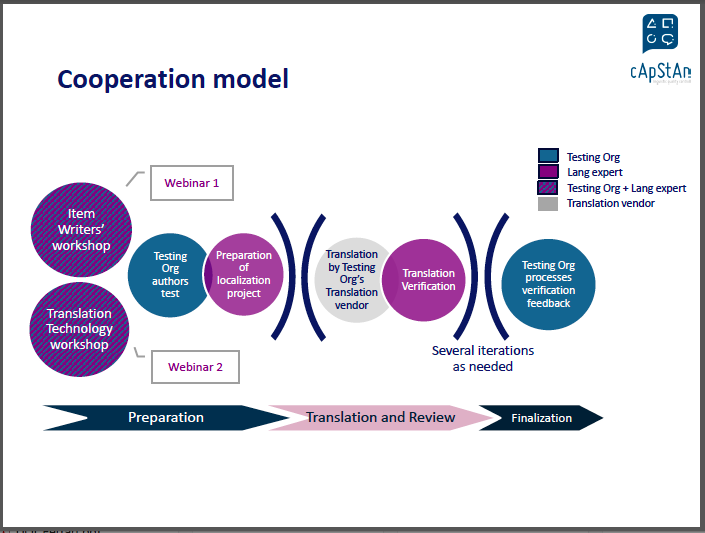
An example of a cooperation model
Item writers can be trained to be more aware of potential translation and cultural issues and linguists can be trained to understand measurement instruments and psychometrics. In item writer workshops the construct that needs to be measured can be examined through the lens of the risks in the different target languages. Translation technology workshops can be useful if the test is being delivered on a platform, as there are implications in terms of user interface/experience across cultures and languages. In the cooperation model below item writers and linguists work together to prepare a localization project, including item-per-item translation guidelines that are used to train the translation teams. Then there is the translation and the translation verification, followed by a review of the verification feedback by the testing organisation, which may or may not lead to a review of the source version for the next round.
Concluding remarks
Many of the potential language item interactions that are due to meaning shifts and perception shifts can be identified well before the data collection instruments are finalised, if the right procedures are set up from the outset, i.e., if there is a multidisciplinary task force, and an item review panel that represents at least a subset of the intended target cultures. This allows to mitigate the potential item bias and fairness issues beforehand. This work is crucial and, if it is not done, you are likely to have issues that are then compounded by the number of languages in which the assessment is administered. It is very important to realize that neither the test authors not the linguists are able to identify all the potential flaws and challenges in a test: that is why piloting, with a fairness filter in mind, remains an integral part of any robust, sound, test development process.