
The elusive encounter of a survey methodologist, a platform engineer and a translation technologist
by Pisana Ferrari – cApStAn Ambassador to the Global Village
For the past two decades the literature has hailed “team translation” as the gold standard in survey translation. Team translation is when you have several translators working separately on the same questionnaire and then they get together and discuss their translations to come to a consensual, agreed, translation. Often there will be an adjudicator, a senior person who will draw the line if they cannot come to an agreement. This translation design is highly recommended in the Cross-cultural Survey Guidelines and has been implemented in numerous research projects, such as the European Social Survey, with a good measure of success in terms of cross-language comparability. But, in those same two decades, technology has also achieved spectacular progress. Areas with noticeable advances include translation technology, with a special focus on computer-assisted translation tools (CAT tools) and automated quality assurance tools. In parallel, new survey administration and delivery platforms have emerged.
Taking stock of progress in translation technology, survey methodology & delivery platforms
One problem is that best practice in survey translation has been tried and tested without taking translation technology into consideration. Team translation was implemented and analyzed first for PAPI, CATI then CAPI questionnaires, and there is a lot of literature about how efficient this has been, but the translation industry has evolved in parallel. Team translation designs have been replicated from one mode to another without really thinking about what would be most suitable for the new technology that has gone mainstream in the meantime.
What happens when you put together a survey methodologist, who will advocate and implement best practice in survey design, a translation technologist, who will want to use and apply the new tools that increase the consistency and quality of the output, and a platform engineer, who has designed and streamlined new questionnaire administration systems and will have his or her own ideas about built-in translation editors? Here is how we imagine an “elusive” encounter and dialogue between them.
Reconciling different priorities and approaches to survey translation
Item writers, platform engineers and translation technologists will have completely different approaches. Let’s imagine a new wave of a 3MC (Multinational, Multiregional, and Multicultural Contexts) survey where the three parties join forces for this survey translation project. Our fictitious characters of the story: Lynn, a survey methodologist and questionnaire author, is a social science researcher by training. Irmtraud is a platform engineer and lead programmer, and an IT scientist by training. Blaise is a translation technologist and terminologist, and an active member of the OmegaT developers community. Lynn would go for a mixed mode survey with team translation meetings and final adjudication; Irmtraud for her part would want to have everything in one place, from question authoring to case management, and have a built-in translation editor; Blaise would want to work on standard-compliant XLIFFS (1) and he is also responsible for aligning the existing translations with the new translations.

How new technology can help
In our hypothetical scenario, the survey requires an advance translation and the workflow envisages a cognitive pre-test done outside the platform. For those who don’t know, advance translations are usually done on a mature draft of a questionnaire, into a subset of the languages in which the questionnaire will be translated and fielded. These translations are made earlier, so that the pilot or the cognitive pre-tests are done not only in the source language but, perhaps, in two or three other languages. Then one observes the reactions of the respondents and these observations feed back into the master questionnaire, where residual ambiguities and complexities can be eliminated. The question arises: how do we translate outside the platform and import them back into the platform in a flawless manner? The platform engineer Irmtraud says that if Lynn wants to use those translations later they will need to be copy-pasted back into the platform. Blaise, the translation technologist, who is “allergic” to copy-pasting as he finds this obsolete, will say that the translatable text should ideally be exported from the platform in the XLIFF format so that advance translation can be done using that standard format. The slide below shows how the workflow could play out.
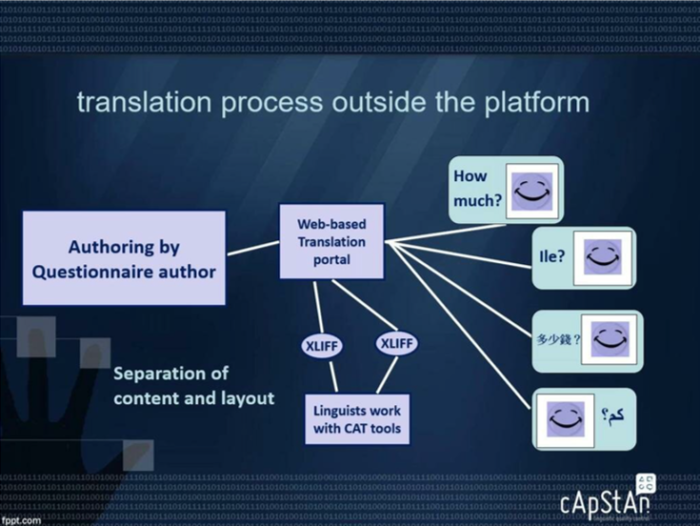
The questions are authored in a questionnaire authoring tool, they are then integrated into a translation management system or web-based translation portal. From there you can preview the questionnaire, with its graphic elements. You can extract the file from this platform, regardless of the programming language, for example in XLIFF, to allow complete separation of content and layout. Linguists will process the XLIFF file, using CAT tools, and once finished, the file can be imported back into the platform. Thanks to all the tags that indicate layout in the XLIFF file, the translated segments will fall into the right places, and the author can see the preview the translations using the web-based translation portal.
XLIFF support for platform engineers
Good news for platform engineers like Irmtraud: there are now open source Java libraries which allow even lay people to read, write and manipulate XLIFF. This should facilitate the adoption of XLIFF as a common standard.
“Segmentation” technology to leverage TMs
In our hypothetical model Blaise might tell Irmtraud that in order to best leverage translation memories he needs to have sentence-based segmentation. Translation memories are not very useful when you have big chunks of text such as paragraphs. Translation memories are most useful when you have short segments,usually sentences or short phrases, e.g. response categories, like “I totally agree, I totally disagree”, etc. Irmtraud might in turn ask him for standards and specifications. Good news again for Irmtraud and all platform engineers: there is a Segmentation Rules Exchange (SRX) they can use. The SRX file will define the segmentation rules and can be shared among different parties. Once you have the segmentation rules on your platform segmentation can be applied consistently in the creation of very different translation “packages” by different people and at different points in time.

Professionalization is the key
In our experience, non-professional translators will prefer a low-tech solution. For example, social scientists who are bilingual and have knowledge of the content but were not trained as translators, or subject matter experts, who usually aren’t linguists. They won’t mind if they don’t have sophisticated translation tools and if they can’t use glossaries and style guides inside the platform. However, we have also seen that reluctance to use more sophisticated tools can be overcome with adequate support (training materials, user-friendly guides with screenshots and step-by-step instructions). Conversely, professional translators work much better if they can use productivity tools. If you want a professional linguist to produce something that is consistent and of high quality you must let him or her work with a CAT tool.
Professionalization will really improve the overall consistency and quality of a questionnaire. XLIFF and other data exchange standards have the potential to streamline the translation process. If you use this technology to its full extent and if you use it correctly, you will gain time, increase quality, increase consistency, achieve economies of scale and efficiency gains. On the other hand, if not used properly, standards can become a prison for translators, they can be corsets, they can be devious! If you want to benefit from the new technologies you do need the support of a translation technologist. Only a translation technologist will be able to handle the level of detail that the data standard does not cover.
Embed translation in survey design for optimal results!
Creating a complex translation workflow for survey instruments will benefit from a multidisciplinary approach. Ideally, survey designers/questionnaire authors, platform engineers, and translation technologists or project managers should work together from the very beginning of a project, from the earliest planning stage. Then you can actually embed translation in questionnaire design and the gains are really incredible. And we can help you to do that!
Read more about our pre-translation Linguistic Quality Assurance (LQA) processes at this link. More preventive linguistic quality assurance before, less corrective action after.
Footnotes
1) XLIFF stands for XML Localization Interchange File Format. It is an XML-based bitext format created to standardize the way localizable data are passed between and among tools during a localization process and a common exchange format for CAT tools.