How a test “travel agent” can help identify the most efficient workflows when assessments, or components thereof, don’t all travel the same routes
by Pisana Ferrari – cApStAn Ambassador to the Global Village
At the recent ATP 2020 global event, a conference gone virtual, our CEO, Steve Dept, presented an innovative approach to test translation and test localisation. He introduced a diagnostic model for a “test travel agent”. Test items do not necessarily take the same translation route: it may be helpful if someone can help identify the most efficient workflows and apply the most appropriate technology. This is where the test travel agent comes in. S/he needs to know about the constructs you want to measure, in what region you would like to measure them, and what your expectations are: scores that are comparable across language versions? Assessments that are valid and fair in the target region? Once the test travel agent is informed, a scenario can be produced: this could be a hybrid approach, with post-edited machine translation for distracting information, and team translation with expert review for sensitive segments; it could also involve cognitive pre-testing in a selection of target languages. The test travel agent can assist in selecting the most suitable localization and quality assurance approach for each component of your test, and connect the dots.
A diagnostic model for a test travel agent
In the case of an e-assessment that needs to be localised the model put forward by Steve suggests profiling it relative to its content, purpose, and to the type of audience. Based on the output, the most suitable workflow for that specific type of content can be selected, and a suggestion can be made for translation technology that would work well with the human linguists and subject matter experts that one might involve in that workflow.
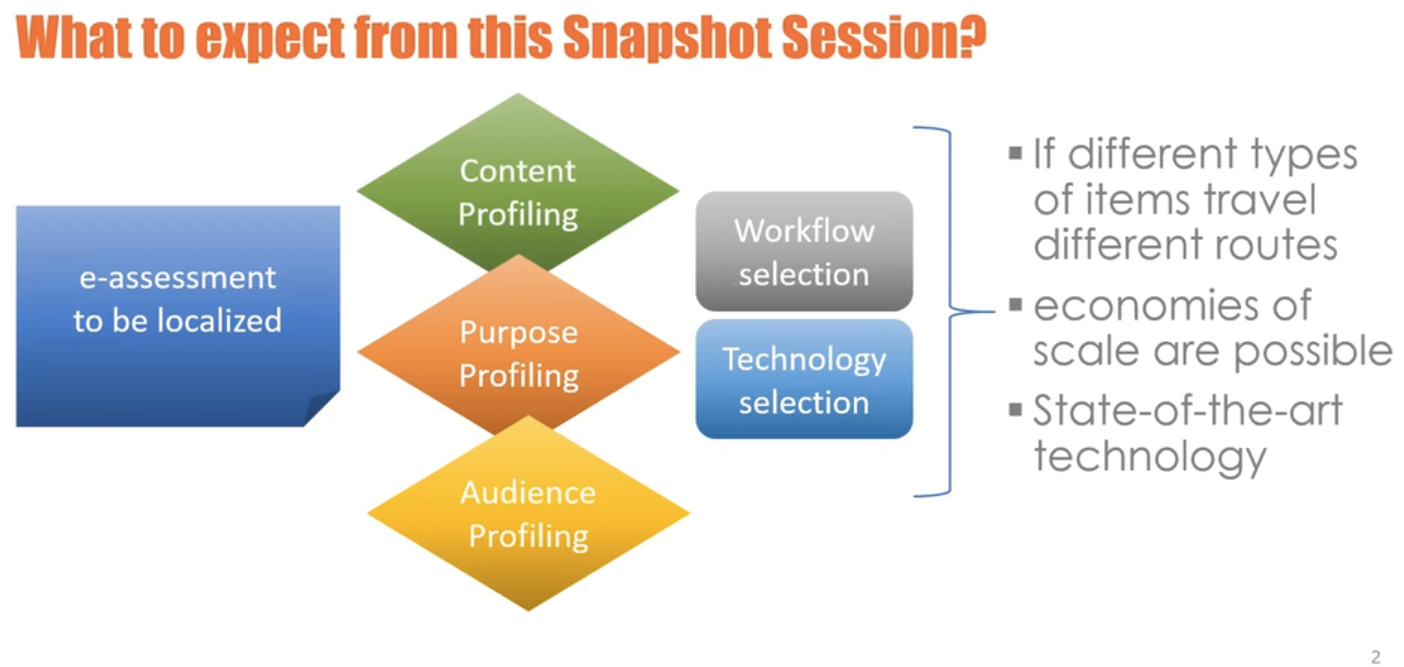
The message that Steve wished to convey in his presentation is that if you have different item types traveling different routes, i.e. different localisation paths, huge economies of scale are possible—without compromising on quality—and that if you use state-of-the-art technology, whether it is inside or outside the testing platform, you can leverage language assets to achieve consistency, higher quality, shorter time to market.
Multiple translation paths and workflows are possible
Just as there are many different ways to travel, there are multiple translation paths and workflows. For example, if you have a stimulus text of say 15-20 web pages that your test takers can browse, and only one of those pages is really relevant to finding the answer to the problem, then some of the translation work can be done with neural machine translation (NMT), followed by (human) post editing.
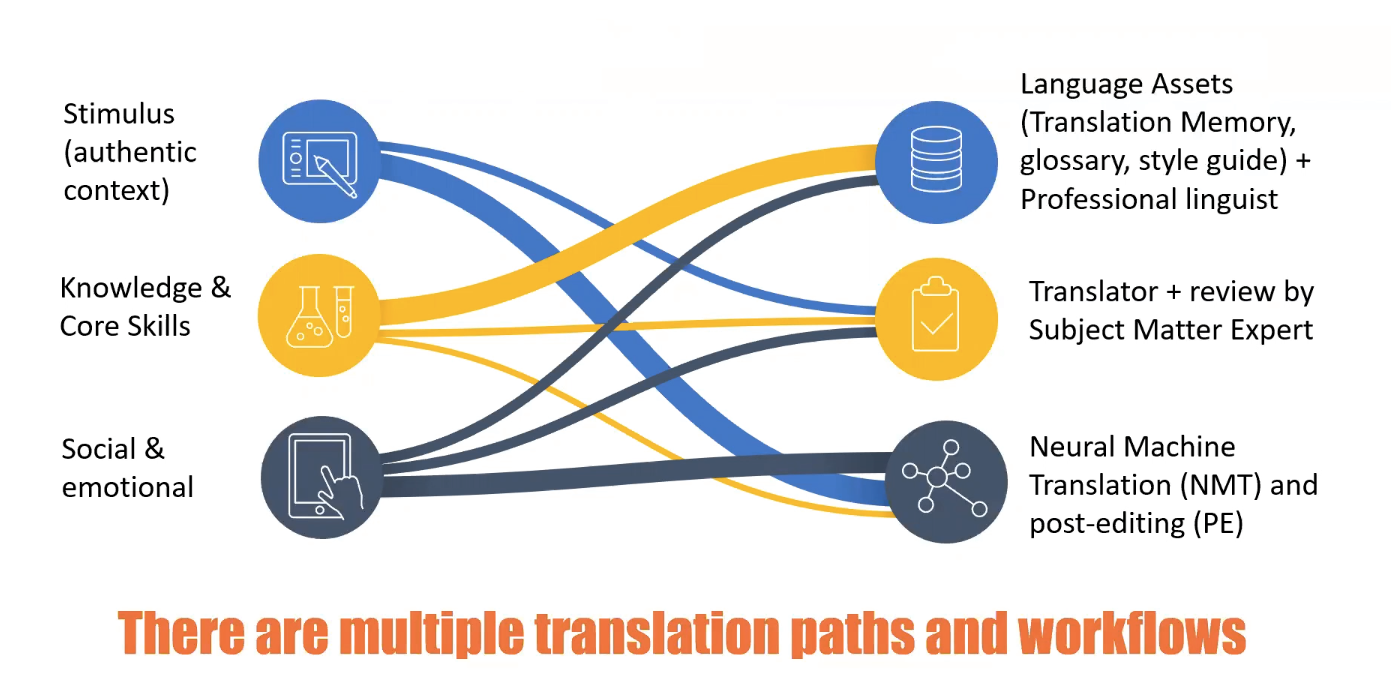
If you are measuring core skills such as literacy and numeracy, there may be some good translation memories available, as well as other language assets (glossaries, that can be reworked, and style guides that can be prepared with formulas). Professional linguists and language assets can take you a long way, says Steve. If the focus is social and emotional skills it may really be advisable to have a psychologist, a bilingual subject matter expert, involved in the translation process. And not just for an external review but in close interaction with the linguists.
Multilevel profiling and multistage branching
What we want to stress, says Steve, is that there is a possibility for testing organisations and psychometricians to leverage multilevel profiling, which, in turn, will allow for multistage branching. The profiling, as we have seen, is done according to content, purpose and audience. NMT is a possible alley, with trained or untrained engines, and with automated translation quality evaluation (TQE) or human post editing (PE) or a combination of both.
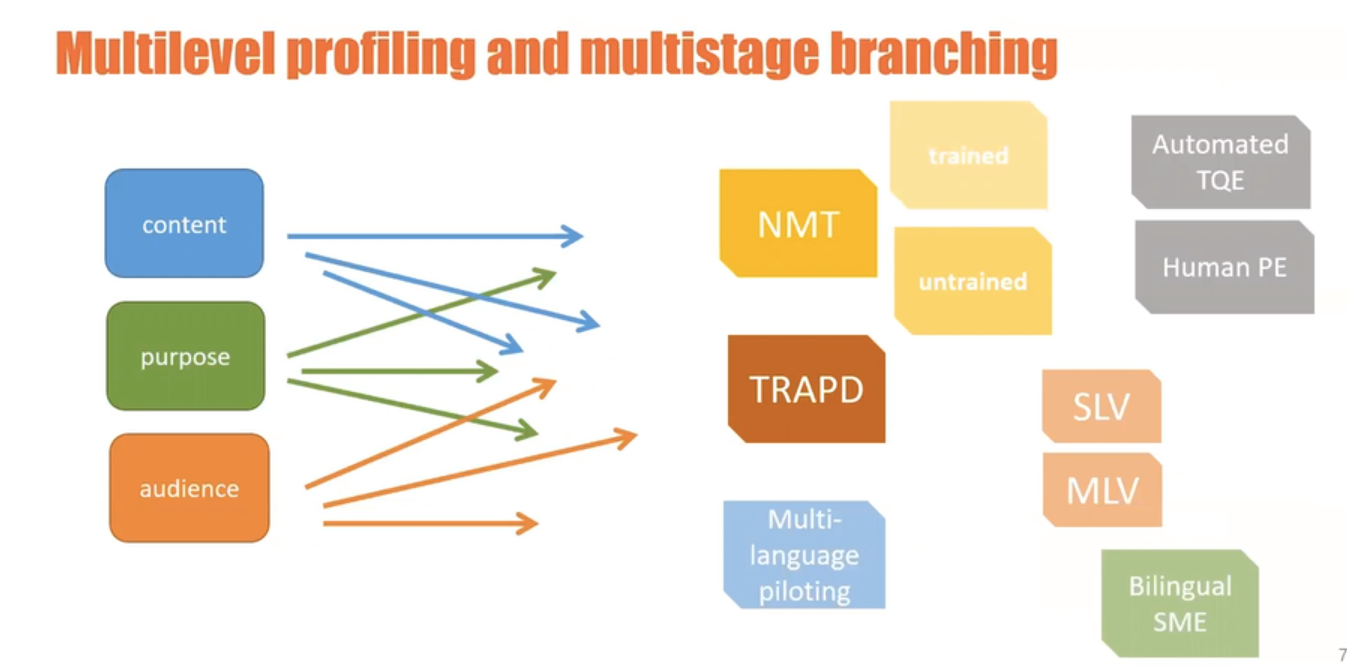
For very sensitive tests that have a lot of nuances you will need something more sophisticated, for example TRAPD (Translation Review Adjudication Pre-testing and Documentation) – a model popularised by the late Prof. Janet Harkness. For this you may decide to use Single Language Vendors (SLVs) or a Multiple Language Vendor (MLVs). Cognitive pre-testing and piloting can also be built in, preferably in at least two or three languages. It is much “safer”, as it allows to see whether the translation actually works as expected in a “production mode” situation. And one can decide at what point to involve a subject matter expert.
Profiling for content, purpose and audience
In profiling for content we link the nature of the test content to the construct one wishes to measure. For example, if a test is designed to measure numerical reasoning, one does not want the respondent to rely on reading proficiency: if the test taker needs to be a really proficient reader to answer the numerical reasoning question you are blurring the lines of your construct.
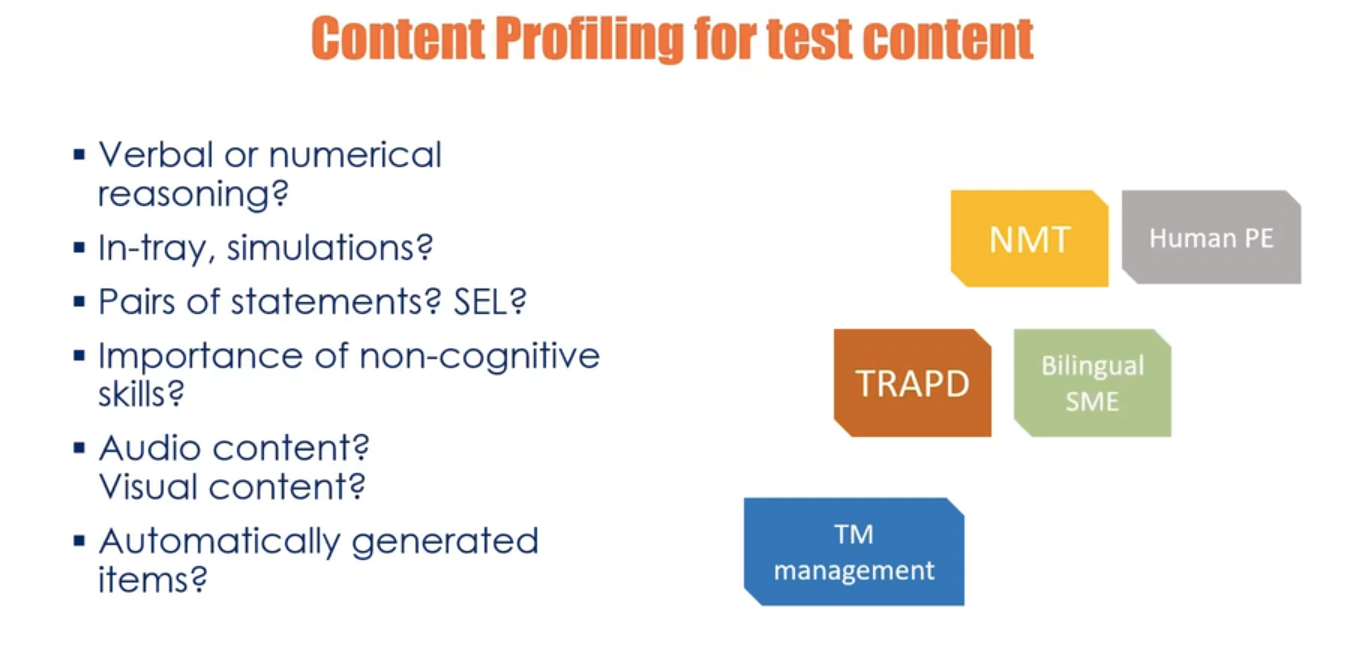
Profiling for content could include, for example:
- In-tray exercises or simulations: you are likely to have a lot of material that is not directly relevant to the test and you can use more NMT, followed by PE.
- A psychological test, e.g. with pairs or triads of statements: this is more sensitive and may require a sophisticated model such as TRAPD, and bilingual SME input.
- Embedded audio or video content: If this content is to be localised considerations need to made about whether to use a male or female voiceover, what type of pitch, what speed of delivery and accent are most suitable, etc. Visual content may also need to be adapted to conform to local culture.
- Automatically generated items: translation memories can be leveraged.
In profiling for purpose, these are some of the key questions to address, and recommendations:
- Is it valid and fair in the target region? – Review by bilingual SME
- Is it comparable across languages? – Monitor verification, post-pilot changes
- Can these constructs be measured? – Examine construct portability in target region
- Long or short content cycle? – Translation memory management particularly useful in long contet cycles
- Single or multimode? – Single source multi-channel (SSMC) publishing model
- High stakes or low stakes? – Single review or multistage review
In profiling for audience language (form of address) and register may play an important role. This may depend on whether the respondents are, for example, K-12 or higher ed students, executives or people in general from different walks of life, or people who are not native speakers of the language of the test (in the latter case one has to avoid elevated register). Finally, translation teams need to take into account the level of difficulty of the test items: translated items need to reproduce that same level of difficulty.
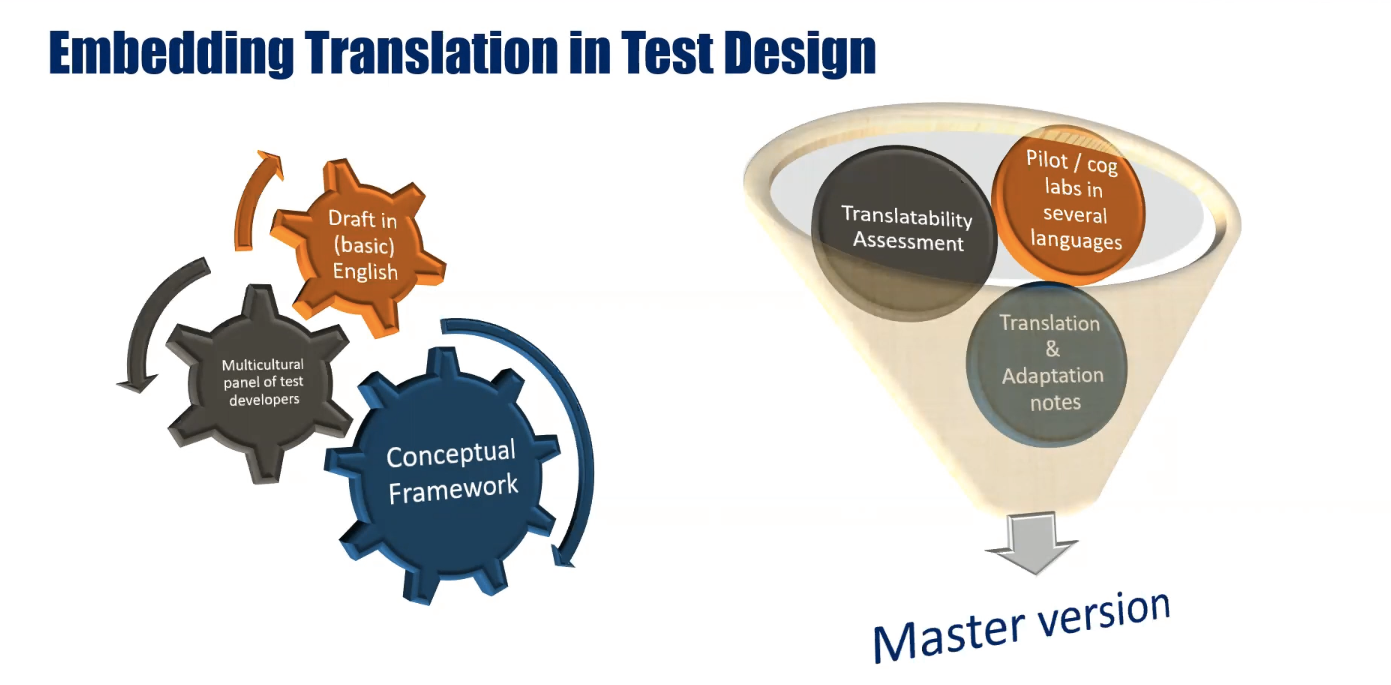
Embedding translation in test design
Unless you are working with an existing test, says Steve, you definitely want to embed translation in your test design. In the course of our 20+ year experience in Linguistic Quality Assurance (LQA), in particular for international large-scale assessments (ILSAs), we have seen that starting with a “more translatable” source version mitigates language/item effects further down the line. Our “translatability assessment” (TA) is a tried and tested method to optimize the master version of an assessment or survey questionnaire before the actual translation and adaptation process begins. Read more about our LQA processes here.
Conclusions
Steve’s concluding remarks and key take home messages:
- Whenever possible, embed translation into test design
- Ask for content profiling and request that workflows be tailored to your assessment
- Bear in mind that a good combination of technology and expertise may come with a hybrid pricing model, e.g. hourly rate for consultancy, Levenshtein edit-distance for post-editing, word count for human translation
- Everybody benefits from transparency!
How cApStAn can help
At cApStAn we have two decades of experience in test translation and linguistic quality control (LQC). We have supervised LQC for international large-scale assessments ILSAs such as PISA, PIAAC, and over 40 other multilingual projects. We specialise in setting up translation/adaptation workflows and work as a trusted language consultant for most major ILSAs. In the private sector we help testing organisations to set up and document their translation process, and, more importantly, to increase the validity and reliability of the different language versions of their tests. We have a standardised methodology to evaluate translation quality, whether it is produced by man or by machine. We have programmers/translation technologists who develop linguistic quality assurance tools inhouse. What characterises cApStAn is our very close relationship with academia. We collect data, we develop empirical frameworks to maximise comparability across different language versions of a test, we develop taxonomies and methodologies and submit them to partners in the academia. They have the means to analyse our data, they make suggestions, amend our frameworks, and eventually they become our prescriptors.