
Scaling Executive Development Tools Across Borders
A case study in applying differentiated localisation strategies to assessments, platform UX or low-stakes content generated on-the-fly.
Scenario
An organisation specialising in Executive Development issued an RFP to localise their entire portfolio into 7 European languages. Their portfolio includes leadership assessments, 360° and pulse surveys, learning materials and follow-up activities, and the user interface of their executive development platform. They sought to partner with someone who could confidently manage diverse content types, applying differentiated workflows to maintain quality and consistency, while leveraging different technological efficiencies.
The organisation wanted a localisation partner capable of working directly within their platform, allowing updates such as new features or patches to be implemented seamlessly, without the need for cumbersome file exports or manual exchanges.
cApStAn’s proposal prevailed. How did the project play out?
A Scalable Solution, Built for the Long Term
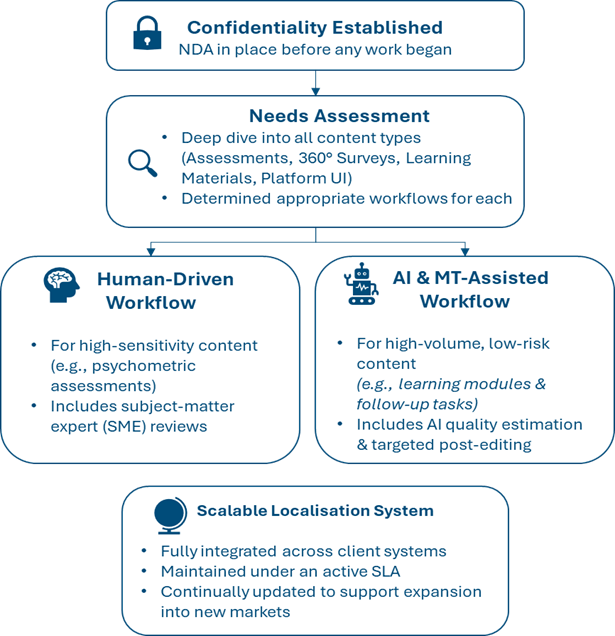
Workflow Analysis
cApStAn’s involvement with this client began with analysis of the types of materials that needed to be translated. We proposed separate but interconnected workflows depending on the unique needs of each content type.
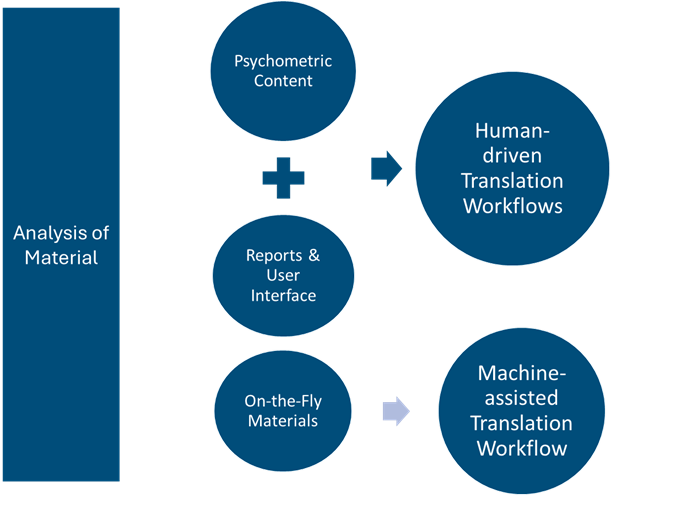
Assessments with psychometric properties or surveys subject to meaning shift without due consideration for context and scope were sent through a rigorous human translation workflow.

Results reports, platform user interface, and other low-stakes materials subject to frequent but scheduled updates were sent through a standard human translation workflow –

Learning materials and other on-the-fly content that is subject to unscheduled updates were sent through a robust machine translation workflow that included AI quality estimation at the start and full human post-editing prior to finalisation –
Human Translation with Subject-Matter Expert Review
The first materials we processed were the client’s psychometric assessments and related surveys. Given that machine translation is not suitable in its current form for maintaining the important psychometric properties of this text type in translation, it was agreed that these materials would undergo a fully human-driven process.
A customised, secure version of the open-source CAT tool OmegaT was used to fetch the client’s materials directly from a GitHub repository. Translators were then able to see the text to be translated without an exchange of files. cApStAn trained the translators and revisors to access the materials and instructed them on key principles of assessment and survey translation and client-specific requirements.
Subject-Matter Experts (SMEs) in the field of psychometrics who are native speakers of the target languages and with professional fluency of English reviewed the translations to ensure proper usage of terminology and that the psychometric properties of the items were maintained in the translation.
Finally, proofreaders implemented the SME edits and did a final pass of the translations to ensure that no minor linguistic issues such as typos or punctuation errors remained in the final delivery. The translations were synced to the client’s repository ensuring that translations were all in the desired format without exchange of files.
The associated reports as well as any platform UI elements underwent a standard single translation and revision process. Since these materials are in the same GitHub repository as the assessments, they were accessible to translators in the same CAT tool and could be checked for consistency across all the client’s materials.
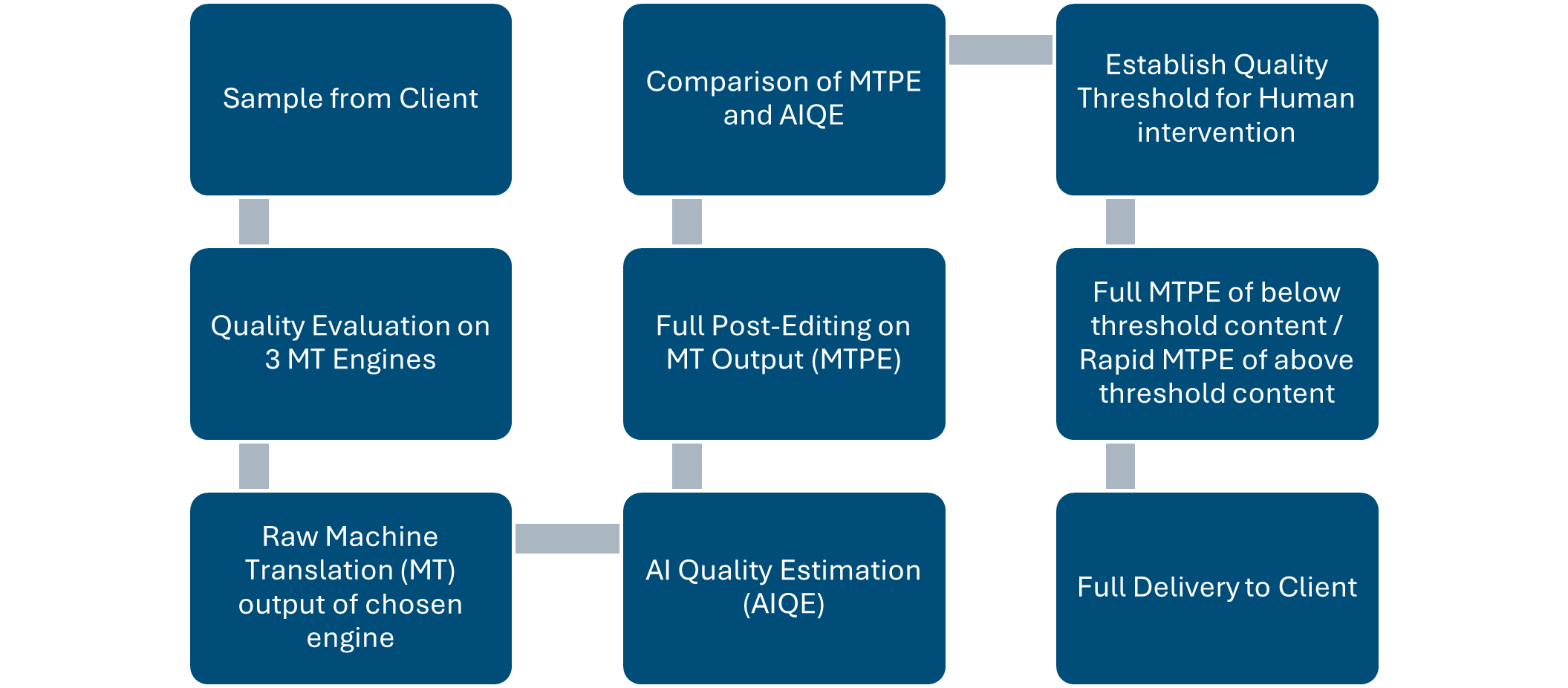
AI Quality Estimation and Machine Translation Post-Editing
Content such as learning materials and follow-up activities was organised in a separate system from the ongoing work on the assessment and platform content. This allowed us to use a dedicated workflow with different technological dependencies to better leverage the AI and MT advances that made it possible to translate the content on-the-fly.
As a first step, a sample of the learning materials was run through three different MT systems and evaluated by human translators in terms of accuracy and fluency. This allowed us to select the MT engine per target language, as not all languages have similar quality outputs across all commonly used engines. Once the most suitable MT was selected, a larger sample was run first through the selected MT and then through an AI Quality Estimation (AIQE) tool, COMET, to evaluate the quality of the MT output on a scale of 0 to 1. This translation was post-edited to human-quality output by our trained linguists and the edit distance of their work was compared against the AIQE score to create a quality threshold.
The quality threshold is unique per target language and uses the following logic: segments with a score of, say, 85% or more of the content will go through rapid post-editing focusing on only minor errors. Segments with a score below the threshold would be fully post-edited by the linguists. This allowed the linguists to focus on areas that were more likely to be problematic for the MT.
Final Results
The outcome is a robust, scalable translation and localisation process. Under a service level agreement (SLA), cApStAn continues to update their materials after several years of collaboration, and we look forward to support their needs as they expand to new markets in future.
Client Feedback
“We have experienced zero delays in releases due to missing translations due to their efficiency as a supplier, including with short notice changes in the product.”
“We have had zero quality complaints in the 2-3 years from end users, despite significant usage, due to the quality of cApStAn’s work.”
“cApStAn’s ability to adapt and implement the MT process has ensured quality is retained, without making cost an insurmountable barrier, as we increased the volume of content in our system by an order of magnitude.”
DO YOU WANT TO TRY OUT THIS PROCESS ON YOUR MATERIALS?
Select some sample items, and request a free pilot or contact us for more details at hermes@capstan.be .